

Researchers from The Chinese University of Hong Kong (CUHK) and MIT have unveiled LongLoRA, a new fine-tuning approach designed to extend the context sizes of large language models (LLMs) efficiently. One of the significant challenges in advancing LLMs has been the substantial computational resources required, particularly when dealing with long text sequences. Traditional methods to train or fine-tune these models for applications like summarizing lengthy documents or answering complex questions have been computationally expensive and, thus, generally inaccessible for most researchers.
LongLoRA aims to address this limitation by introducing a dual-strategy approach. First, the research presents a attention mechanism called Shift Short Attention (S2-Attn). This technique allows for efficient information sharing among different subgroups of data during the training phase. The segmented approach does not require extra computational power, yet it enables the model to understand and process longer contexts efficiently. Second, LongLoRA revisits and improves upon an existing low-rank adaptation technique known as LoRA. The researchers found that by making the embedding and normalization layers trainable, they could significantly improve the model’s performance in handling extended contexts.
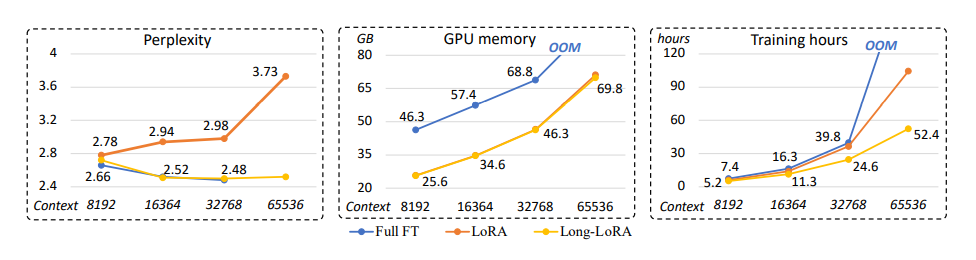
What sets LongLoRA apart is its remarkable efficiency. According to the team, it can be implemented in just two lines of code during the training phase and requires no changes during the inference stage. The researchers demonstrated LongLoRA’s effectiveness through extensive testing, showing that it could fine-tune a model with up to 100,000 tokens of context on a single 8× A100 machine—something considered computationally prohibitive until now. Additionally, LongLoRA retains compatibility with existing techniques, such as FlashAttention-2, which means it can easily integrate into current AI infrastructures.
To further contribute to the field, the team has released a dataset called LongQA, featuring more than 3,000 long context question-answer pairs. This dataset is expected to be a valuable resource for improving the conversational abilities of large language models. In essence, this research signifies a monumental step in making the development and fine-tuning of large language models more efficient and less resource-intensive. The team believes that LongLoRA has the potential to be compatible with various types of large language models and position encodings, opening new avenues for applications requiring the understanding of extended text sequences. The full research paper, code, and dataset have been made publicly available, adhering to the open-source ethos of the AI community.
Read full paper: https://arxiv.org/abs/2309.12307





{kind=link}
inventore quia et rerum repellat deleniti iste sint voluptate est sit ut. doloremque ab adipisci fugiat fuga error aut sequi voluptatibus nihil nesciunt voluptatum autem. voluptas dolore hic architecto minus et neque rerum blanditiis ipsa ab sint.