

In a recent development, Tencent AI Lab has launched AutoPrep, a preprocessing framework explicitly crafted for in-the-wild speech data. This innovative framework is positioned to change the landscape of speech data processing by offering automated preprocessing and high-quality annotation for unstructured speech data, addressing the longstanding challenges in the field.
The utilization of extensive open-sourced text data has advanced text-based Large Language Models (LLMs) in recent years. The speech technology community is still struggling to fully exploit large-scale speech data due to the inherent limitations and lack of quality annotations in publicly available datasets. These datasets are compromised by background noise, speech overlapping, incomplete transcriptions, and missing speaker labels, which severely limit their applicability in developing advanced speech models.
AutoPrep has been introduced to tackle these issues, providing a comprehensive solution that enhances speech quality, automates speaker labels, and produces accurate transcriptions. The framework encompasses six crucial components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering, and automatic speech recognition. These components work in tandem to transform raw, in-the-wild speech data into high-quality, annotated speech data that can be readily employed in various speech technology applications.
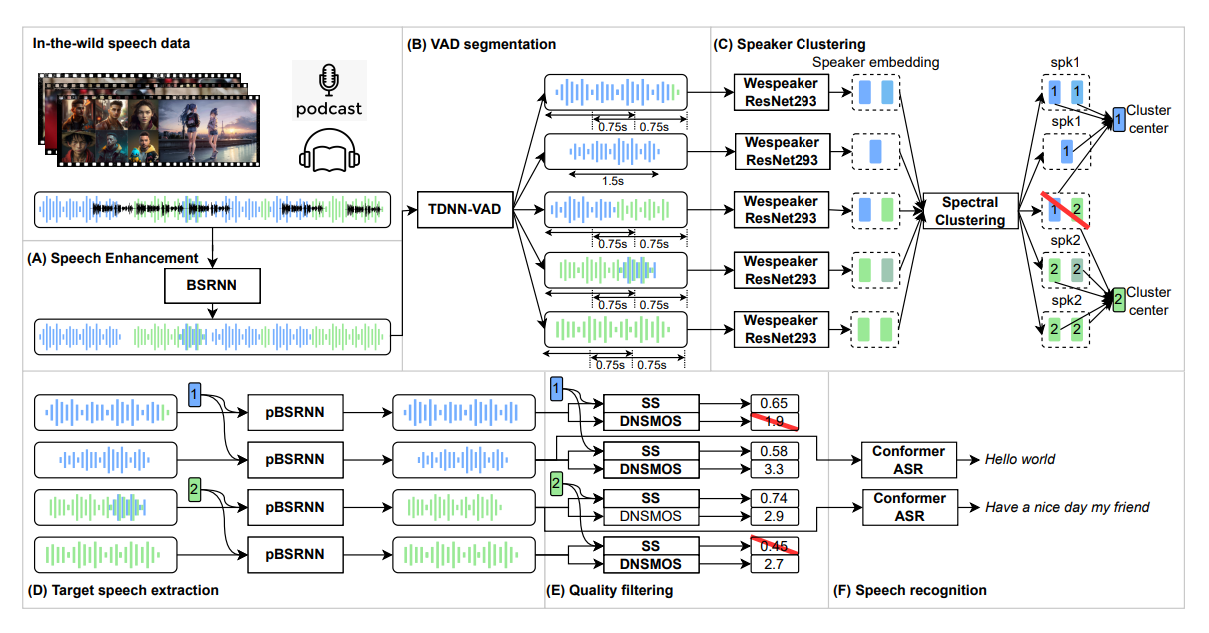
Experiments conducted on the open-sourced WenetSpeech and the self-collected AutoPrepWild corpora have demonstrated AutoPrep’s remarkable efficiency and reliability, achieving comparable DNSMOS and PDNSMOS scores to other open-sourced Text-to-Speech (TTS) datasets. The processed data from AutoPrep can be directly utilized in a plethora of tasks such as TTS, Speaker Verification (SV), and Automatic Speech Recognition (ASR) model training, providing a user-friendly experience and allowing selective customization of the data for diverse usage scenarios.
Beyond its primary function of improving speech quality, AutoPrep has shown its profound impact on Text-to-Speech (TTS) synthesis, validating its effectiveness through the training of a multi-speaker TTS model based on the DurIAN TTS model. The results have underscored AutoPrep’s capabilities, showing significant improvements in the mean opinion score (MOS) and speaker similarity MOS (SMOS) score, thereby highlighting the framework’s contribution to enhancing speech quality and overall effectiveness in speech technology applications.
AutoPrep stands as a symbol of Tencent AI Lab’s dedication to propelling research and development in speech technology. By providing automated and high-quality preprocessing and annotation of in-the-wild speech data, AutoPrep is the way for advancements in speech models, especially in applications requiring high-quality speech recordings with multiple speakers and styles, such as TTS.
In conclusion, Tencent AI Lab’s AutoPrep is a monumental advancement in speech technology, offering a solution to the challenges of processing unstructured, in-the-wild speech data by delivering automated, high-quality annotations and enhanced speech quality. AutoPrep is not just a technological innovation; it is a catalyst for future developments in speech technology, setting the stage for more refined and advanced models in the field.
Check full paper: https://arxiv.org/abs/2309.13905





{kind=link}